변수명 한글로 작성해도 문제가 없을까?(feat.유니코드)
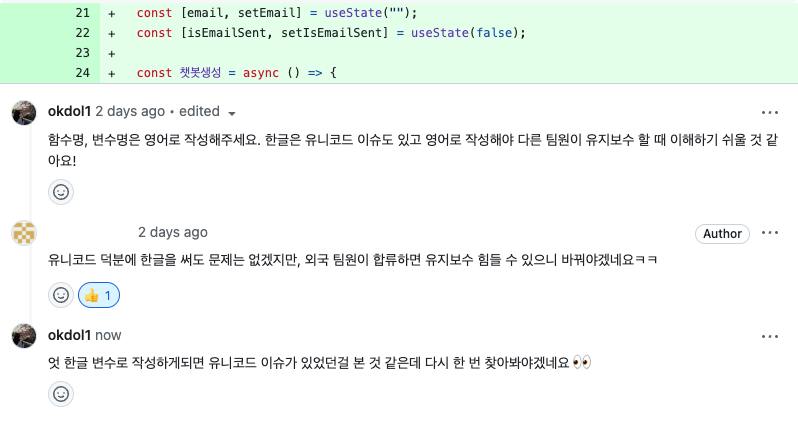
팀원분께서 변수명을 한글로 작성하신 것을 보고 한글변수명은 유니코드 이슈가 있었던 것 같아 위와 같이 리뷰를 남겼는데 문제가 없다는 코멘트를 보고 변수명 한글로 작성해도 문제가 없을까?라는 의문이 생겨 조금 더 자세히 유니코드에 관해 찾아보게 되었다.(나무위키에 유니코드와 한글에 대해 잘 정리되어 있는데 굉장히 재밌다.)
먼저 유니코드란 무엇일까?
유니코드(Unicode)는 전 세계의 모든 문자를 다루도록 설계된 표준 문자 전산 처리 방식이다.
유니코드 덕분에 다양한 언어와 특수 문자, 이모지😄👍🔥 까지 하나의 통일된 형식으로 처리할 수 있다.

옛날에 이런 한글깨짐 현상을 본 적이 있다. 이는 문자열 셋이 통일이 안되었던 시절 문자열 셋과 인코딩 방식이 맞지 않아 글자들이 깨지는 일들이 생겨나게 되었다.(아스키 코드 사용하던 시절)
이 문제들을 해결하고자 나온게 바로 유니코드다.
유니코드를 UTF-8 등으로 인코딩을 해서 사용할 수 있다.
- UTF-8: 문자 인코딩 방식 중 하나
유니코드의 역사
- 1991년 10월: v1.0.0 → 최초 버전 발표
- 1992년 6월: v1.0.1 → CJK 공통한자 정의
- 1993년 6월: v1.1 → 기존 한글 2,350글자에 추가 4,306글자가 할당
- 1996년 7월: v2.0 → 한글 대이동 사건
- 이때 한번 할당된 문자는 더이상 옮기지 않는다는 원칙이 생김
- 2022년 9월 14일: v15.0
유니코드와 한글
- 유니코드에서 한자 다음으로 많은 코드를 차지하고 있는 한글 문자다. 왜 저렇게 많냐면 현대 한국어 음절 조합과 한글 자모를 모두 집어넣었기 때문이다.
- 한글의 경우, 현대 한국어의 자모 조합으로 나타낼 수 있는 모든 완성형 한글 11,172자(가, 각, 갂, 갃, …, 힠, 힡, 힢, 힣)이 모두 들어가 있다. 그래서 쿈이나 슌처럼 한글 채움 문자 없이 KS X 1001에서는 쓸 수 없는 글자들도 전혀 문제없이 쓸 수 있다.
- 또한 U+1100 ~ U+11FF, U+A960 ~ U+A97F, U+D7B0 ~ U+D7FF에 배당된 한글 자모는 한글을 조합형으로 구현할 수 있게 초·중·종성을 일일이 배당했다. 여기에는 옛한글 낱자들도 같이 포함되어 있다. 그래서 ᄒᆞᆫ과 같은 옛한글도 옛한글 전용 글꼴만 있으면 문제없이 쓸 수 있다.
- 따라서 유니코드에는 조합형, 완성형 모두 표현할 수 있다. 주로 조합형은 옛한글을 표현할 때 쓰임. 이유는 옛한글을 하나하나 배당하면 유니코드 전체를 뒤덮고도 남기 때문
한글 전산화
유니코드는 1991년부터 한글을 지원하기 시작했고, 이후 버전에서는 더 많은 한글 문자와 옛한글까지 지원했다. 그러나 당시 한국에서는 유니코드를 사용할 충분한 이유가 없었으며, 조합형 한글 지원도 제대로 되지 않아 문제가 있었다. 배열 순서도 불규칙했고, 추가되어야 할 글자들도 제대로 추가되지 않았다. 유니코드 1.1을 지원했다가 피를 본 사례도 있다.(대표적으로 오라클 DB)
그래서 대한민국 대표는 유니코드 2.0 제정 시 완성형 현대 한글 11,172자를 가나다순으로 새 영역에 배당할 것을 요청했다.
이 요청에 대해 각국 대표들 사이에서 논쟁이 오갔지만, 결국 대한민국 대표의 요청이 받아들여져서 1996년 발표된 유니코드 2.0에서 1.1 때까지 U+3400 ~ U+4DFF에 배당되어 있던 한글 6,656자를 없애고 새 영역(U+AC00 ~ U+D7A3)에 가나다순으로 11,172자를 배당했다. 이렇게 배당된 11,172자가 2.0부터 현재까지 한글·한국어 처리에 쓰이고 있다. 이로 인해 유니코드 2.0 이상과 그 이전 버전은 서로 호환되지 않는다. 그리고 이 '한글 대이동 사건'을 계기로 2.0부터는 한 번 배당한 문자는 절대 옮기거나 없애지 않는다는 정책을 세웠다.
이 11,172자는 남한의 가나다순으로 배당되었다. 남한과 북한은 한글 낱자의 정렬 순서가 다른데, 북한이 이것을 문제 삼아 이 11,172자를 북한식으로 재배열해 줄 것을 2000년경에 요구했으나, 이미 한글은 코드 위치가 한 번 대이동한 전례도 있고 문자를 절대 옮기거나 없애지 않는다는 정책에도 위배되기 때문에 보기 좋게 씹혔다.ㅋㅋ (지금 북한은 울며 겨자 먹기로 남한 순으로 배당된 11,172자를 쓰고 있다고 한다)
유니코드 덕분에 문자 인코딩 호환성을 보장하고 있어 한글로 변수명을 작성해도 문제될 일이 없다고 한다.(가끔 개발 환경에 따라 텍스트 에디터나 IDE가 한글 유니코드를 제대로 해석하지 못할 수 있다고 하는데 요즘 사용하는 에디터들은 모두 문제될 게 없다고 한다.)
그럼 왜 한국에서는 여전히 영어로 변수명을 작성하고 있는걸까?
- 영어 대소문자를 이용해 식별자의 종류를 구분할 수 있다.
- 변수, 함수: camelCase
- 상수: 대문자와 언더스코어를 사용
- 클래스, TS 인터페이스: PascalCase
- …
- 자동 완성
- 프로젝트의 표준화 통일성과 일괄성
- 협업하는 프로젝트, 누구나 읽을 수 있어야 함
그럼 항상 영어로 작성하는게 좋을까? 그건 또 아닌 것 같다.
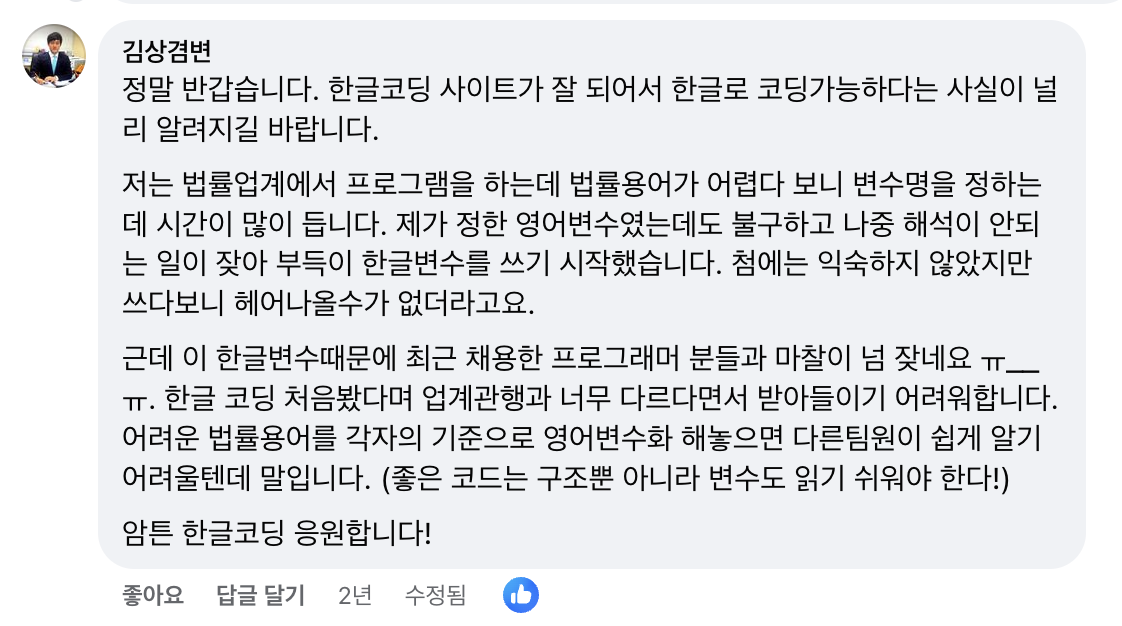
- 토스페인먼츠도 한글 변수명 사용 세종대왕 프로젝트 (한글 코딩 컨벤션)